Waarom u niet zonder een Disaster Recovery Plan (DRP) kunt

De permanente dreiging van cyberaanvallen, natuurrampen of materiële defecten nopen de organisaties tot het invoeren van een stevig Disaster Recovery Plan (DRP). Dit artikel buigt zich over wat een DRP precies is en waarom het van essentieel belang is voor de informatica van een B2B-bedrijf. Hoe gaat u tewerk?
Wat is een Disaster Recovery Plan (DRP)?
Een DRP (Plan tot herstel na een ramp) omvat alle procedures en policies opgesteld door een organisatie om de storingen en de schade veroorzaakt door onvoorziene incidenten zo veel mogelijk te beperken. Het is erop gericht om na een ontwrichtende gebeurtenis de activiteiten zo snel mogelijk opnieuw normaal te laten verlopen. Het DRP is specifiek van toepassing op de informatica-infrastructuur van een bedrijf. Zijn doel bestaat uit het beschermen van de data, de systemen en de kritieke applicaties.
Het DRP is in de eerste plaats - zo vinden wij bij Win - een collectief werkstuk, waarbij mensen betrokken zijn van binnen en buiten het bedrijf.
Waarom moet je je voorbereiden op een ramp?
Enkele zorgwekkende cijfers: 60% van de administraties heeft geen continuïteitsplan wanneer er zich een ernstig incident voordoet voor de kritieke resources, volgens Digital Wallonia (2022). 24% beschikt over een verzekering die een financiële en/of technische bijstand waarborgt bij een schadegeval.
40% van de bedrijven die te maken krijgen met het verlies van gegevens loopt volgens Gartner een reëel risico om binnen de 5 jaar teniet te gaan. Sterker nog: Gartner geeft de organisaties die te maken krijgen met een ernstig incident en die geen continuïteitsplan hebben, een resterende levensduur van maximum 13 maanden.
Gegevensverlies kan heel wat oorzaken hebben (natuurramp, brand, menselijke fout, materieel defect, pogingen tot hacking, enz.) en de impact ervan kan heel zwaar zijn, en kan zelfs leiden tot de definitieve stopzetting van de activiteiten.
Daarom moet je kunnen beroep doen op een DRP dat voor jou werd uitgedacht en dat werd opgesteld rekening houdend met jouw specifieke activiteiten.
Opstellen van een herstelplan: de NIST-aanpak
De NIST-aanpak is één van de methodes waarmee 1 Disaster Recovery Plan kan worden opgesteld en uitgestippeld.
Het NIST (National Institute of Standards and Technology) publiceert sinds 1988 normen, richtlijnen en goede praktijken voor het cybersecuritymanagement van de organisaties. Dit instituut maakt deel uit van het Amerikaans Ministerie van economie.
Het NIST heeft een Cybersecurity Framework (CSF) vastgesteld om aan de hand van een stappenplan de organisaties te helpen om hun beveiliging beter te beheersen.
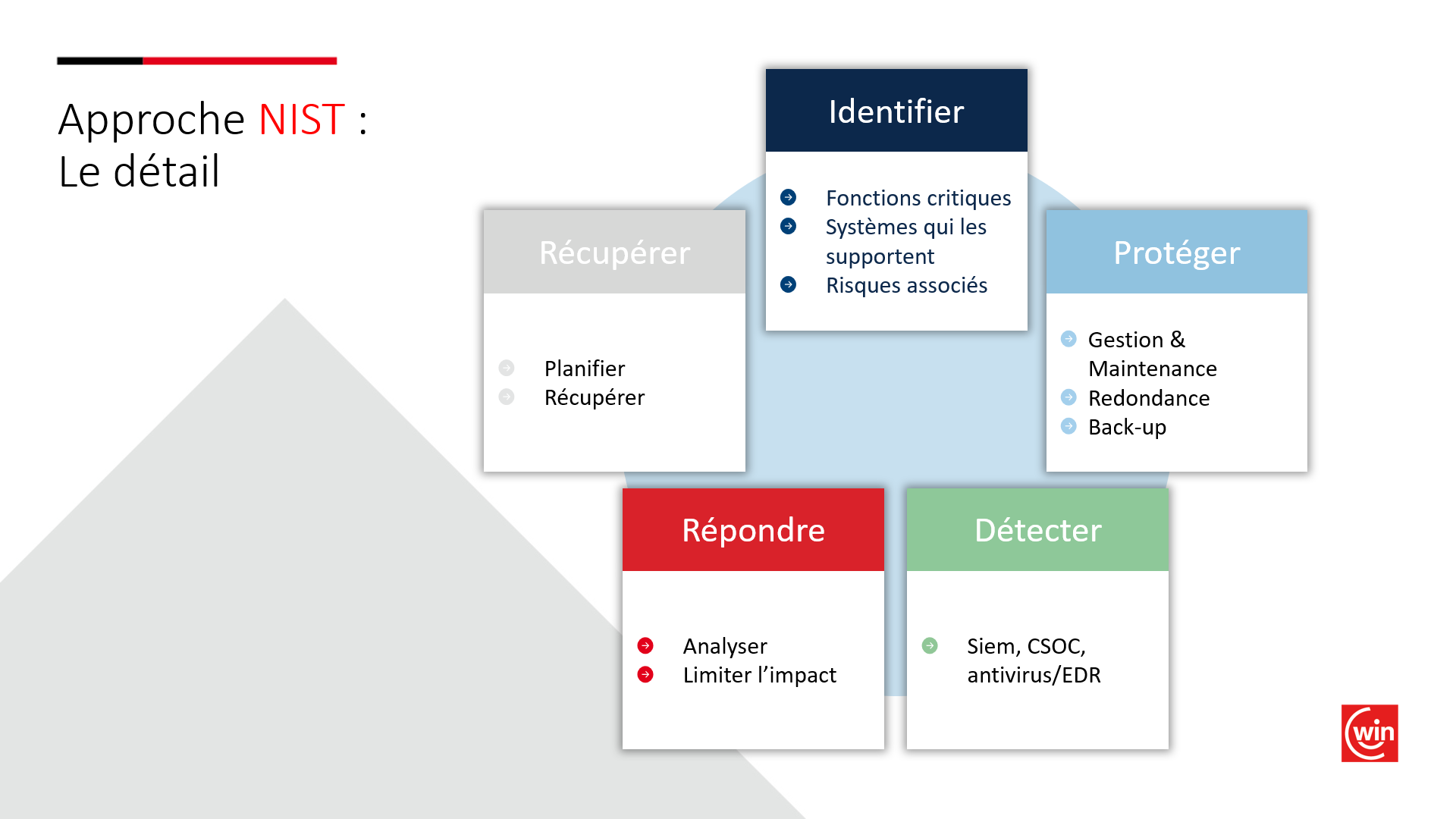
Identificeren: In een eerste fase moet je begrijpen hoe je organisatie werkt, welke de kritieke afdelingen zijn en de systemen onderzoeken die deze afdelingen ondersteunen. Doel: de risico's en bedreigingen in kaart brengen die gepaard gaan met de kritieke resources van jouw organisatie.
Beschermen: beschermingsmiddelen worden ingevoerd om de risico's te beperken (bv.: back-up, redundante systemen, enz.)
Detecteren: de potentiële of reële veiligheidsincidenten worden gedetecteerd dankzij de implementatie van een veiligheidsbeleid en verdedigingsinstrumenten zoals SIEM, CSOC, EDR, enz.
Reageren: wanneer een veiligheidsincident wordt gedetecteerd, worden onmiddellijk maatregelen genomen om het incident in te dammen, de impact te evalueren en te bepalen welke reactie moet worden gegeven.
Herstellen: bedoeling van deze stap is het herstellen van de normale activiteiten van de organisatie.
Het bepalen van je hersteldoelstellingen
Na de potentiële risico's te hebben geïdentificeerd (brand, overstroming, cyberaanvallen, enz.), en de potentiële impact te hebben geanalyseerd (inkomstenderving, aantasting van reputatie, gegevensverlies, enz.), worden voor elke kritieke dienst de hersteldoelstellingen bepaald. Met een goed ontworpen DRP wordt de onderbrekingstijd (downtime) zoveel mogelijk beperkt dankzij de erin voorziene maatregelen voor preventie, detectie en snelle respons.
Er moeten twee elementen worden vastgesteld, de RPO en de RTO.
De RPO (Recovery Point Objective) is de aanvaardbare tijdspanne waarin er potentieel data verloren gaat. Bijvoorbeeld: als je om de 24u een back-up maakt, verlies je dus mogelijks 24u aan gegevens. De RTO (Recovery Time Objective) is de maximaal aanvaardbare tijdspanne tussen een incident en het opnieuw operationeel zijn om onaanvaardbare gevolgen voor de activiteiten van de organisatie te vermijden.
Anders gezegd: Hoelang mogen de diensten stilliggen en welke hoeveelheid data mag er verloren gaan?
Om deze cruciale vraag te beantwoorden, moet je de relevante diensten/activiteiten/informatiesystemen analyseren en hun beschikbaarheid afwegen ten opzichte van de kosten.
Herstelstrategieën
Je kunt verschillende beschermings- en redmiddelen bedenken, naargelang de doelstellingen die je hebt bepaald. In de DRP moeten de specifieke strategieën worden opgenomen die moeten worden toegepast om snel opnieuw operationeel te zijn. Het gaat bijvoorbeeld om het veiligstellen van de kritieke data, over noodsites en beschikbaar personeel om het herstel uit te voeren, enz.
Maar hoe kies je de beste maatregel(en)? Door na te gaan welke maatregelen van toepassing zouden kunnen zijn voor jouw organisatie en door de kost van elk van deze maatregelen af te wegen ten opzichte van een mogelijke onderbreking van de activiteit en de impact hiervan op je organisatie.

Wat de reservekopieën (back-ups) betreft, bestaan er een aantal vuistregels:
- Maak 3 verschillende kopieën van de data
- Op 2 verschillende dragers/media
- 1 externe kopie
- 1 van de kopieën is niet geconnecteerd of is onverplaatsbaar
- 0 fouten bij het testen van de back-up- en herstelprocessen
Bij een schadegeval moeten drie maatregelen achtereenvolgens worden genomen: eerst moeten de kritieke workloads worden geïdentificeerd. Vervolgens moeten deze datastromen, die op de back-ups staan, opnieuw worden aangezet in DRP-modus. En tot slot worden deze datastromen zonder haast opnieuw overgezet naar hun oorspronkelijke plaats.
De goede praktijken
De definitie van een DRP steunt op een vrij eenvoudige premisse: hoop op het beste, maar wees voorbereid op het slechtste scenario in geval van een ramp. Een DRP legt immers de procedures vast waarvan je hoopt ze nooit te moeten gebruiken voor het herstel van de systemen en toepassingen.
Concreet neemt het de vorm aan van een document dat de onmisbare elementen bevat waar je rekening mee moet houden in geval van een herstel na een incident:
De doelstellingen: welke zijn de kritieke functies die moeten worden hersteld en binnen welke tijdspanne?
De scenario's: heropstart in DRP-modus (deel dat minstens moet worden heropgestart en opnieuw operationeel moet zijn) of in "full"-modus voor een zo volledig mogelijk herstel?
De rollen en verantwoordelijkheden: wat is de rol van elk lid van het team dat deel zal nemen aan het DRP?
De inventaris van de resources (infrastructuur, netwerken, materiaal, dienstenleveranciers, enz.) nodig voor het herstel van de activiteit.
De methodologie: de IT-impact, de migratie van de IP-adressen, het beschikken over de nodige opslagcapaciteit en virtuele machines, bijvoorbeeld.
De procedures: de beschrijving van de stappen die moeten worden gevolgd om de activiteit te herstellen, en dit zowel op operationeel vlak als wat betreft de interne en externe communicatie.
Eenmaal het DRP werd opgesteld, zal het jaarlijks getest worden om bijvoorbeeld de resultaten (qua timing/snelheid) te vergelijken met de vooraf bepaalde verwachtingen (RTO/RPO). Het plan moet regelmatig tegen het licht worden gehouden zodat je steeds steunt op een plan dat overeenstemt met de realiteit van je organisatie (evolutie van de organisatie, van de technologieën, van de risico's).
DRP: de oplossingen die tot uw beschikking staan
Zoals we hebben kunnen vaststellen, is een Disaster Recovery Plan geen werk van improvisatie. Er is een heel gamma van oplossingen beschikbaar om uw herstelstrategie inhoudelijk vorm te geven:
- Back-up: Win werkt met wereldwijd erkende VEEAM-oplossingen om te zorgen dat de data stand houden dankzij beveiligde back-upsystemen en snelle en betrouwbare hersteloplossingen, in gelijk welke omgeving.
- Beveiliging en Netwerk: met een volkomen beveiligd netwerk bent u beschut tegen indringers. Een redundante connectiviteitsoplossing kan tussenkomen wanneer een hoofdverbinding wordt onderbroken.
- SOC : de CyberSOC zorgt voor een voortdurende monitoring van uw informatiesysteem. Het gaat om een team van deskundigen dat zorgt voor de beveiliging van uw organisatie.
- Cloud Agilis met een private cloud- of hybri cloud-aanpak op maat van uw organisatie.
- Azure by Win: Een Azure public cloud voor u beheerd door Win voor de niet-gevoelige data van de onderneming (omwille van de Cloud Act).
- Datacenter in België: het WDC is een soeverein datacenter gevestigd in Villers-le-Bouillet, waar uw gevoelige data kunnen worden gehost (territorialiteit van data), waar u over ruimte beschikt voor uw data, uw servers en ander materiaal (switch, storage-controller, enz.) alsook over zalen om uw teams in onder te brengen wanneer er zich op uw site een incident voordoet.
- Begeleiding en advies bij het uitwerken van een DRP.
Conclusie
Een DRP is een compleet plan waarmee u doeltreffend crisissituaties kunt managen en doeltreffend en sereen uw kritieke activiteiten kunt herstellen in geval van een ernstige storing. Dit stappenplan is essentieel en het moet een gezamenlijk werkstuk zijn van zowel de IT-teams als alle andere afdelingen van uw organisatie.
De ene organisatie is de andere niet: elke sector heeft zijn eigen prioriteiten. Het is dus uiterst belangrijk dat elke structuur op basis van haar specifiek karakter bepaalt welke diensten/informaticasystemen prioritair moeten worden hersteld.